⚠ 如果公式不正常显示可以使用Chrome浏览器或者重新刷新试试
一般分为两种显著性目标检测(salient object detection)和眼注视点显著性(eye fixation saliency),虽然两者都能展现吸引用户注意力的物体或者区域,但是侧重点不同。物体的显著性主要在于图像中各个物体轮廓的检测,例如目标检测,语义分割等等都涉及到物体的显著性;眼注视点的显著性更多是关注用户观看的区域,和用户的观看行为有联系。由于用户在观看全景视频时,往往会关注视频中比较突出的部分,所以两者也有交集。

- 参考1:显著性目标检测
- 参考2:图像显著性检测算法的评价指标介绍
1. 眼注视点显著性
Receiver Operating Characteristic curve(ROC)
Area Under Curve(AUC)
Viewport-based Saliency Prediction提到这个不太好?
shuffled AUC(sAUC)
ROC 曲线又称受试者受试者工做特征曲线,以假正例率(False Positive Rate, FPR)为横轴,真正例率(True Positive Rate, TPR)为纵轴所组成的坐标图,以0~255不一样的阈值对预测的眼注视点显著图分类描点,从而绘制成曲线图。从直观上看,曲线越接近左上角,说明该算法检测性能越好;曲线下面积称之为AUC, AUC越大说明算法检测性能越好。因为AUC会受中心误差(center bias)的影响,研究者又提出更加鲁棒的sAUC评价指标。
Pearsons Linear Correlation Coefficient(CC)
CC$\uparrow$是指皮尔逊相关系数,也是线性相关系数,用来评价预测的眼关注点显著图和参考图ground truth之间的线性相关性,CC越大说明该模型性能越好
协方差:$Cov(X,Y)=\frac{\Sigma_{i=1}^n(x_i-E(X))(y_i-E(Y))}{n}$
感性的理解,如果数据杂乱,正负抵消,那么这个协方差就很小,就谈不上二者相关;如果数据很一致,想么协方差就负的比较多(负相关),要么就是正的比较多(正相关)
消除x和y的量差,引用皮尔逊相关系数:$\sigma_{X,Y}=\frac{Cov(X,Y)}{\sigma_X·\sigma_Y}$
具体对于显著性而言,P和D分别代表saliency map和fixation map,被视为随机变量
$CC(P,Q)=\frac{Cov(P,Q)}{\sigma(P)\times\sigma(Q)}$
参考:https://blog.csdn.net/limiyudianzi/article/details/103437093
Normalized Scanpath Saliency(NSS)
NSS$\uparrow$是指标准化扫描路径显着性,用来评价二者之间的差别值,NSS越大说明模型性能越好;
$NSS(P,Q)=\frac{1}{N}·\Sigma_i({\overline P_i}\times Q_i)$
其中P是saliency map,Q是fixation map的二值图,其中i是像素的下标,N是所有的像素值总数,N is the total number of fixated pixels,$\overline P=\frac{P-\mu(P)}{\sigma(P)}$
这里说明一下,一般论文中NSS指标都是5.0+左右,很显然如果我们将预测saliency map归一化在0-1之间,我们得到的NSS只能在0-1之间,因此我觉得论文中计算NSS值可能是将saliency map归一化至0-10之后再计算的
Kullback-Leibler Divergence (KLDiv)
KLDiv$\downarrow$是指KL散度,Kullback-Leibler (KL) 是一种广泛使用的信息论度量,用于衡量两个概率分布之间的差异。KLDiv越小说明该模型检测性能越好。
$KL(P,Q)=\Sigma_iQ_ilog(\epsilon+\frac{Q_i}{\epsilon+P_i})$
其中$\epsilon$表示正则化常数,KL是非对称差异度量
具体再参考:https://blog.csdn.net/matrix_space/article/details/80550561
参考1:What Do Different Evaluation Metrics Tell Us About Saliency Models? IEEE TPAMI 2019
参考2:Deep Visual Attention Prediction IEEE TIP 2018
2. 显著性目标检测
Mean Absolute Error
MAE是指平均绝对值偏差,用于评价预测的显著图和参考图之间的差别,MAE越小说明该算法性能越好;
$ MAE \downarrow =\dfrac{1}{W\times H}\sum{W}{x=1}\sum{H}{y=1}| \overline{S}(x,y)-\overline{G}(x,y) | $
PR曲线
Precise是差准率,Recall是查全率,将图像二值化之后计算:
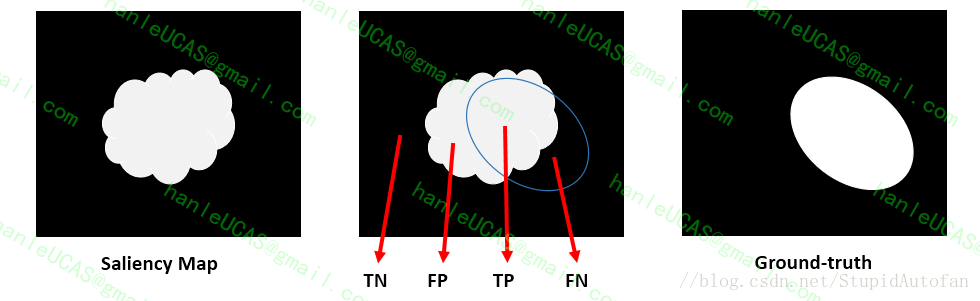
$Precision=\frac{TP}{TP+FP}$ 以及 $Recall=\frac{TP}{TP+FN}$
将输出图片S进行二值化时,阈值选择为从0到255,每取一个阈值,即可对所有输出图S算得一组相对应的Precision值与Recall值。最后将所有图像在该阈值下的Precision值与Recall值分别求平均,最后将会得到256对P,R值,以Recall为横坐标,Precision为纵坐标绘制曲线图即可得到precision-recall (PR)曲线。
F-measure
查全率和查准率在非负权重β下的加权调和平均值(Weighted Harmonic Mean) ,计算公式如下:
$F_\beta \uparrow =\frac{(1+\beta^2)Precision*Recall}{\beta^2Precision+Recall}$
$\beta^2$一般取值为0.3,即增加了Precision的权重值,认为查准率比查全率要重要些。因为当模型将输出图全部标为目标区域时,查全率Recall将等于100%,但是查准率Precision却很低。
- ROC (Receiver Operating Characteristic curve)
- AUC (Area Under Curve)
- MAP (Mean Average Precision)
- MAR (Mean Average Recall)
上述评价指标中,ROC与AUC相似于眼注视点任务,都是用不一样的阈值来肯定描点位置,而后将全部点链接起构成ROC曲线;
MAP是指平均精度率,MAR是指平均召回率,MAR和MAP越大说明算法性能越好。
3. 如何得到fixation map
根据用户实际的注视点,统计得到(可能需要去除那些saccade场景的注视点)
可以参考:A Saliency Dataset for 360-Degree Videos



